|
|||||
|
Главная
 Теория и практика судебной экспертизыПортретная экспертизаИ. Л. Журавлев, А. Ю. Соколов, А. А. Кадейшвили. Эффективность идентификации и верификации лиц нейронной сетью при низком качестве фотоизображений Теория и практика судебной экспертизыПортретная экспертизаИ. Л. Журавлев, А. Ю. Соколов, А. А. Кадейшвили. Эффективность идентификации и верификации лиц нейронной сетью при низком качестве фотоизображений
| |||||
|
| |||||
И. Л. Журавлев, А. Ю. Соколов, А. А. Кадейшвили (г. Москва, OOO «Вокорд Софтлаб»)
Проведено исследование достоверности идентификации и верификации лиц алгоритмом на основе нейронной сети для изображений различного низкого качества. Получены среднестатистические ошибки 1-го и 2-го рода на базе изображений 3530 лиц, построены зависимости ошибок от разрешения изображений и степени искажений, обусловленных цифровым сжатием JPEG. Определён порог ухудшения верификации, равный межзрачковому расстоянию L=24–32 пикселов при отсутствии цифровых искажений JPEG. При обработке JPEG порог для качества компрессии соответствует качеству 60 (L=48 пикселов) и 80 (L=32 пикселов), ниже данного качества наблюдается ухудшение распознавания. Изображения с указанными характеристиками и выше характеризуются достоверностью распознавания 70–80 % (FRR =20–30 %) в точке ложноположительного принятия решения 1:1000000 (FAR=1E–6). Идентификация в тестовых группах с L =16–48 пикселов (без сжатия) и L=32–48 с качеством сжатия JPEG выше 40 характеризуется эффективностью выше 90 % с рангом R=10 на списке поиска размером 3.5 тыс. изображений. Вероятность идентификации при отсутствии компрессии JPEG меняется незначительно вплоть до значений межзрачкового расстояния L=24 пикселов. Ключевые слова: нейронные сети; идентификация лиц; верификация изображений лица; среднестатистические ошибки первого и второго рода; достоверность распознавания лиц.
Ж91 ББК 32.972:67.53 УДК 004.4:343.983 ГРНТИ 10.85.31; 50.41.25 Код ВАК 05.13.11; 12.00.12
I. L. Zhuravlyov, A. Yu. Sokolov, A. A. Kadejshvili. Efficiency of identification and verification of persons by a neural network at low quality of pictures
I. L. Zhuravlyov; A. Yu. Sokolov; A. A. Kadejshvili (Moscow city, LLC «Vokord Softlab»)
In the work the reliability of identification and verification of faces by an algorithm based on a neural network for images of different low quality was studied. The average errors of the 1st and 2nd kind are obtained on the basis of images of 3530 persons, the dependence of errors on the resolution of images and the degree of distortion due to the digital compression of JPEGs are constructed. A threshold of verification impairment equal to the interpupillary distance L = 24–32 pixels is determined in the absence of digital JPEG distortions. When processing JPEG, the threshold for the quality of compression corresponds to the quality of 60 (L = 48 pixels) and 80 (L = 32 pixels), a degradation of recognition is observed below this quality. Images with the specified characteristics and above are characterized by the recognition accuracy of 70–80 % (FRR = 20–30 %) at the point of false-positive decision making 1: 1000000 (FAR = 1E–6). Identification in test groups with L = 16–48 pixels (uncompressed) and L = 32–48 with JPEG compression quality above 40 is characterized by an efficiency above 90% with a R = 10 rank on the search list of 3.5 thousand images. The probability of identification in the absence of compression JPEG varies slightly up to interpupillary distance L = 24 pixels. Keywords: neural network; face identification; verification of facial images; the average errors of the first and second kind; the accuracy of face recognition. _____________________________________
Среди современных компьютерных алгоритмов для распознавания образов наибольшую эффективность продемонстрировали алгоритмы на основе глубоких нейронных сетей и машинного обучения [1, 2]. Нейронные сети также лидируют среди методов по распознаванию и идентификации лиц [3, 4]. Известно, что в экспертно-криминалистической практике и судебной портретной экспертизе исследуемые изображения часто характеризуются низким разрешением и повышенными шумами, что обусловлено сложными условиями освещения, использованием различных видеокамер с низким разрешением либо с широким углом зрения, цифровым кодированием фото- или видеоизображений. Возможность использовать автоматические методы идентификации цифровых изображений в этих условиях требует обоснования. Целью работы является исследование нейросетевого алгоритма идентификации лиц, разработанного в компании Вокорд [5], и продемонстрировавшего высокие показатели в тестах [6], на изображениях с изменяющимся качеством, а также выявление критических характеристик изображений, до которых алгоритм сохраняет работоспособность. В качестве тестовой базы изображений лиц была выбрана часть базы FaceScrub размером 3530 изображений достаточно высокого качества (расстояние между глазами на каждом лице – не менее 50 пикселов) [7]. Опираясь на эти изображения, путём передискретизации были построены тестовые изображения более низкого разрешения. Все новые изображения нормировались на заданное межзрачковое расстояние L=48, 32, 24, 16 и 12 пикселов. Новые изображения для L=48 и L=32 были дополнительно подвергнуты дальнейшей обработке – сжатию JPEG c различной степенью качества. В результате, было получено несколько групп изображений тех же самых лиц, но различного разрешения и качества. На рис. 1 приведены примеры лиц из различных групп. Тестировался нейросетевой алгоритм распознавания лиц, разработанный компанией Vocord версии 3.0, занявший первое место в категории «идентификация» в международном тесте Megaface в 2016 году [6]. В данном алгоритме применялись одновременно несколько предварительно обученных нейронных сетей, общий объём их весовых коэффициентов, характеризующий глубину и сложность сетей, составляет ≈ 2 Гб. Итоговый вектор признаков лица f на выходе сети имеет размер 512 байт. Сравнение двух изображений выполняется путём сопоставления итоговых векторов признаков. Скорость сравнения составляет 10 млн/сек пар векторов признаков на одном ядре процессора i7. Скорость построения вектора признаков равна примерно 1,6/сек на процессоре, либо 15/сек на графическом ускорителе NVIDIA GTX TitanX.
а) L=48 пикселов и без компрессии
б) L=48 пикселов и без компрессии
в) L=12 пикселов и без компрессии
г) L=48 пикселов, качество JPEG = 20
д) L=48 пикселов, качество JPEG = 20 Рис. 1 Примеры из тестовых групп изображений различного качества
1. Статистические критерии оценки эффективности распознавания. Результатом сравнения алгоритмом двух векторов признаков f1 и f2 является некоторое число S, называемое степенью схожести: S=S(f1, f2), 0<S≤1. На одинаковых изображениях (f1=f2) S=1. Чем выше S, тем более похожи изображения сравниваемых лиц друг на друга. Для оценки эффективности использовались два общепринятых сценария тестирования – идентификация и верификация. 1.1. Идентификация. В тестовой группе изображений для каждого человека с номером i присутствует несколько Mi (примерно 30) его разных изображений. В тесте вначале фиксировалось одно произвольное изображение человека Xi из Mi. Из оставшихся Mi –1 изображений этого же человека выбиралось ещё одно иное его изображение Yi, которое смешивалось со всеми другими изображениями всех отличных от заданного человека лиц, что формировало группу поиска Zi. Все изображения Zi ранжировались по списку по критерию максимальной степени похожести S на исходное изображение Xi. Таким образом, каждый раз в списке поиска присутствовало только одно второе изображение Yi разыскиваемого человека, и множество изображений других лиц, общее их число ≈ 3500. На первое место ставилось изображение с максимальным значением похожести S, на второе место – следующее за максимальным и т. д. Человек i считался распознанным с рангом R, если его разыскиваемое изображение Yi находится на месте R от начала ранжированного списка. Эксперимент повторялся для каждого изображения человека Xi из Mi, и для каждого пробного второго его изображения Yi. Общая эффективность идентификации характеризуется процентным количеством правильно найденных людей в зависимости от ранга, усреднённая по всем людям и по всем изображениям Xi и Yi. Для эксперта-криминалиста данный сценарий аналогичен задаче поиска подозреваемого по большой базе данных. Требуется отобрать из всех изображений наиболее похожие, чтобы сузить поиск. Сужение списка может производиться до одного изображения (R=1), до 10 изображений (R=10), до 100 изображений (R=100) и т. д. 1.2. Верификация. Другим сценарием сравнения лиц является верификация, то есть установление, принадлежат ли два сравниваемых изображения лица одному и тому же человеку? Такой сценарий аналогичен судебной портретной экспертизе двух изображений лица. При автоматическом сравнении решение о совпадении принимается, если степень схожести на выходе алгоритма выше заданного порога P, значение которого устанавливается обычно достаточно высоким: S(f1 ,f2)>P (1) Если условие (1) выполняется, то принимается, что пара изображений принадлежит одному человеку. При идентификации с критерием (1) возможны два типа ошибок: – ложноположительная ошибка, то есть принятие разных людей за одинаковых. Число таких ошибок увеличивается с уменьшением порога P, и, наоборот; – ложноотрицательная ошибка, то есть принятие одинаковых людей за разных. Число таких ошибок увеличивается с увеличением порога P, и, наоборот. Одновременно не удаётся подобрать такие значения порога, чтобы обе ошибки стремились к нулю. Чем выше количество ошибок первого рода, тем меньше ошибок второго рода, и, наоборот. Рабочее значение порога может выбираться из статистической оценки точности алгоритма по этим двум ошибкам и из условий задачи. Статистическая оценка точности базируется на двух величинах: средней ошибке ложного положительного принятия (в иностранной литературе – «false acceptance rate»)
и средней ошибке ложного отказа (в иностранной литературе – «false rejection rate»)
Здесь N+ – общее число ложноположительных ошибок при заданном пороге, N– – общее число ложноотрицательных ошибок, N – общее число всех сравнений. В данной работе при тестировании изображений проводились парные сравнения, в зависимости от порога вычислялись ошибки и определялись значения FAR и FRR по всему количеству парных сравнений внутри заданной группы. На основе этих значений были построены графики зависимостей FRR от FAR для тестируемых групп изображений. 2. Результаты Результаты идентификации и верификации представлены на графиках ниже. 2.1. Идентификация
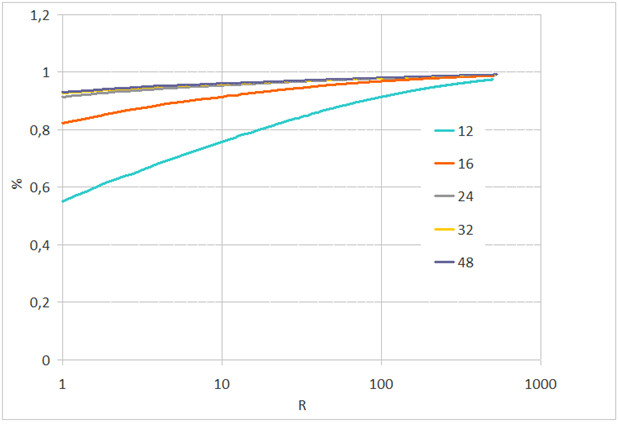
Рис. 2. Вероятность идентификации в зависимости от ранга R при различном межзрачковом расстоянии при отсутствии сжатия JPEG
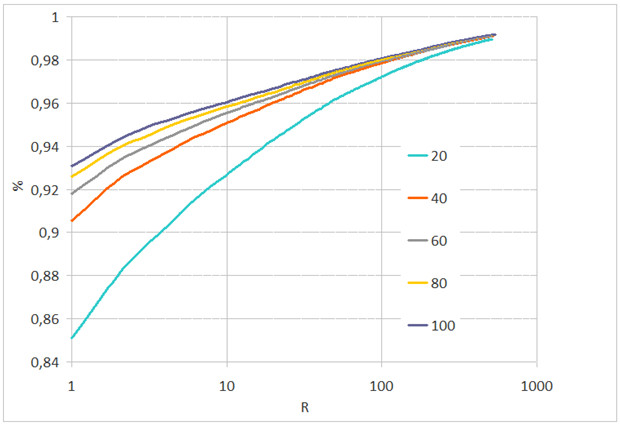
Рис. 3. Вероятность идентификации в зависимости от ранга R при различном качестве сжатия JPEG и межзрачковом расстоянии L=48 пикселов
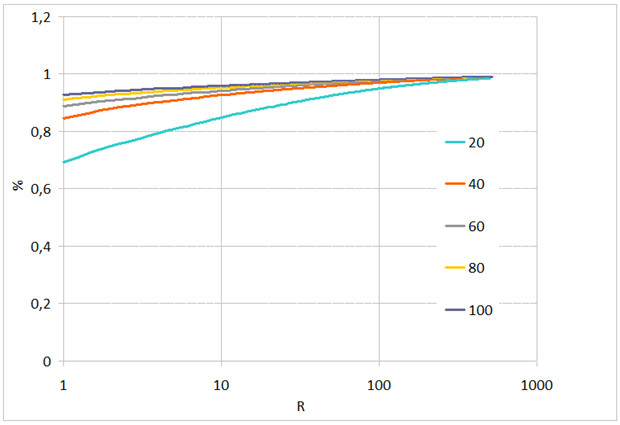
Рис. 4. Вероятность идентификации в зависимости от ранга R при различном качестве сжатия JPEG и межзрачковом расстоянии L=32 пиксела
2.2. Верификация
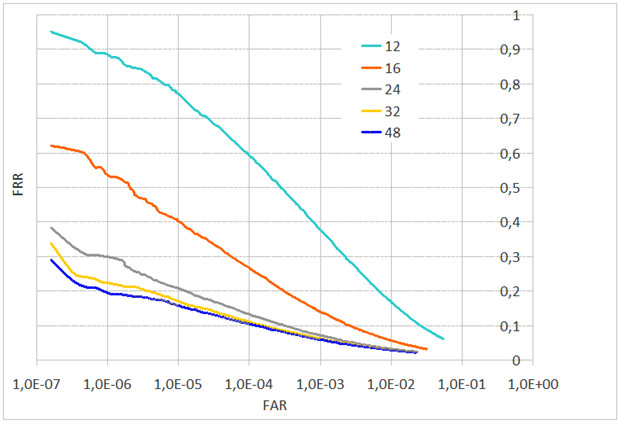
Рис. 5. FAR от FRR в зависимости от межзрачкового расстоянии L при отсутствии искажений JPEG
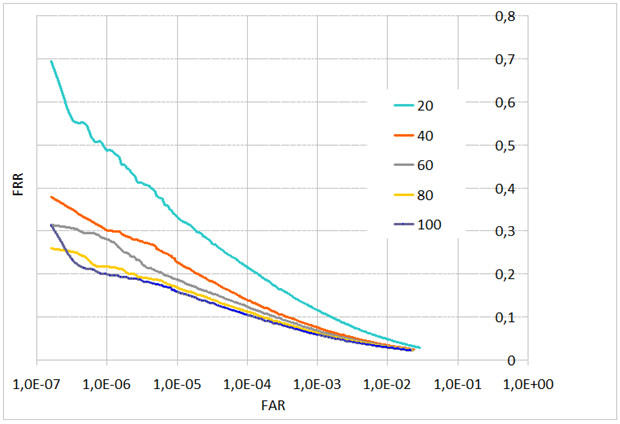
Рис. 6. FAR от FRR в зависимости от качества сжатия JPEG (межзрачковое расстояние L=48 пикселов)
Выводы В тесте с идентификацией при отсутствии искажений, обусловленных дополнительным сжатием JPEG, вероятность идентификации меняется незначительно вплоть до значений межзрачкового расстояния L=24 пиксела (рис. 2). Для значений L=48 и 32 пиксела ухудшение распознавания за счёт сжатия JPEG наблюдается при степени качества сжатия ниже 60 (рис. 3, 4). При этом в тестовых группах L =16–48 пикселов (без сжатия) и L=32–48 пикселов с качеством сжатия JPEG 40 и более наблюдается идентификация выше 90 % с рангом R=10.
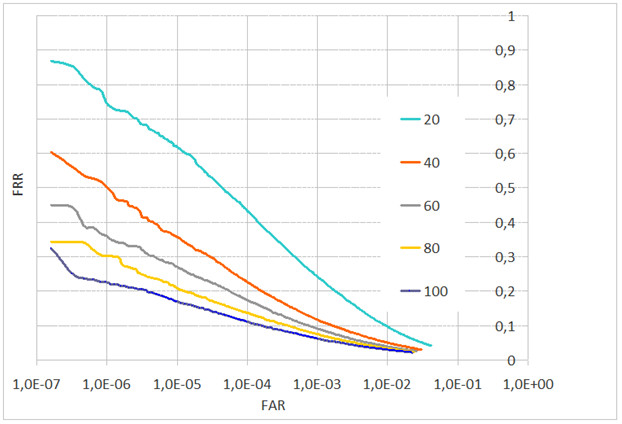
Рис. 7. FAR от FRR в зависимости от качества сжатия JPEG (межзрачковое расстояние L= 32 пиксела)
В тесте с верификацией при отсутствии искажений компрессии JPEG кривые ошибок для межзрачкового расстояния L=48 и L=32 пиксела отличаются незначительно (рис. 5). Отличие наблюдается при переходе к межзрачковому расстоянию L=24 пиксела и меньше. Для L=24 пиксела в точке FAR=1E–6 FRR меняется с 20 до 30 % (рис. 6, 7). Сжатие JPEG ухудшает распознавание, при L=48 пикселов отличие проявляется при качестве сжатия 60 и ниже. При L=32 пиксела отличие наблюдается при переходе от качества 100 к качеству 80.
Литература: 1. Ciresan D.; Meier U.; Schmidhuber J. (June 2012). "Multi-column deep neural networks for image classification". 2012 IEEE Conference on Computer Vision and Pattern Recognition. – New York: Institute of Electrical and Electronics Engineers (IEEE): 3642–3649. 2. Krizhevsky Al. ImageNet Classification with Deep Convolutional Neural Networks. // Advances in Neural Information Processing Systems 25 (NIPS 2012). 3. Yaniv Taigman, Ming Yang , Marc’Aurelio Ranzato, Lior Wolf. DeepFace: Closing the Gap to Human-Level Performance in Face Verification // Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, 23–28 June 2014 4. Schroff F., Kalenichenko D., Philbin J. FaceNet: A Unified Embedding for Face Recognition and Clustering. // Computer Vision and Pattern Recognition, (CVPR) 17 June, 2015. 5. http://www.vocord.ru/www.vocord. ru 6. http://megaface.cs.washington.edu/results/facescrubresults.html 7. http://vintage.winklerbros.net/facescrub.html Комментарии (0)
Пока никто не оставил комментарий.
| |||||
|
| |||||
|
| |||||
|
| |||||
|

|
| Выполняется запрос |





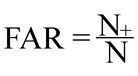 (2)
(2)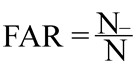 (3)
(3)